Autom8: A Claude Orchestrator
github.com/louisboilard/autom8 | crates.io | docs.rs
Intro & Objectives
At the moment of writing this, orchestrators I have been exposed to
have sane concepts but the implementation lacks the things we aim
to bring with autom8: type safety, determinism where possible
(i.e autom8 does as much work as possible, only leverage Claude
when needed), safe re-runs/resuming of interupted work, ratatui
powered TUI to monitor on-going runs and investigate/review previous
runs, a native desktop GUI for richer workflows, proper error/state
types, sane toml based config files, intelligent context injection
between agents via git diffs and shared context, concrete agent types,
commits/pr creations if desired, git worktree support for parallel
execution, context size optimization..
Some of these exists in
orchestrators that I believe are massively overengineered or in
others that are very much underengineered (multiple thousand
lines of shell scripts, or requiring a bunch of external deps
or spawning multiple agents at the same time and basically tell
them to "figure it out" and "self correct").
Autom8 therefore aims to improve on already existing concepts (agentic loops, context sharing between iteratively spawned agents..) in a simple way: a single binary, one command to run, cross platform, rich per-project configuration, sane defaults, easy to interface with.
Let's take a look.
Architecture Overview
autom8 is structured around three core concepts: specs, state, and knowledge.
A spec defines what needs to be built. It's a JSON file listing user stories with acceptance criteria, priorities, and a pass/fail status for each. The spec is the source of truth for "what work remains."
{
"project": "my-feature",
"branchName": "feature/add-auth",
"userStories": [
{
"id": "US-001",
"title": "Add login endpoint",
"acceptanceCriteria": ["POST /login returns JWT", "Invalid creds return 401"],
"priority": 1,
"passes": false
}
]
}
State tracks execution progress. Every transition gets persisted to disk, so the orchestrator can resume from any point. The state includes the current machine state, which story is being worked on, iteration counts, and timestamps.
Knowledge accumulates across the run. When a story completes, autom8 captures what files were modified, what architectural decisions were made, and what patterns were established. This knowledge gets injected into subsequent prompts, giving later agents context about earlier work.
The component relationships look like this:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Spec │ │ RunState │ │ ProjectKnowledge│
│ (what to do) │────▶│ (where we are) │────▶│ (what we know) │
└─────────────────┘ └─────────────────┘ └───────────────── ┘
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
└─────────────▶│ StateManager │◀─────────────┘
│ (persistence) │
└─────────────────┘
│
┌───────┴───────┐
▼ ▼
state.json runs/*.json
(current) (archived)
The StateManager handles all persistence. Current state
lives in a single file that gets updated on every transition. When a run
completes, it's archived with a timestamp for later reference.
The State Machine
Current impl is a 12-state machine with explicit transitions. Every state is a discrete phase of execution.
#[derive(Debug, Clone, Copy, PartialEq, Serialize, Deserialize)] #[serde(rename_all = "kebab-case")] pub enum MachineState { Idle, LoadingSpec, GeneratingSpec, Initializing, PickingStory, RunningClaude, Reviewing, Correcting, Committing, #[serde(rename = "creating-pr")] CreatingPR, Completed, Failed, }
At a higher level there are 4 main steps, the user only runs `autom8`
to go through all 4.
First is planning/spec creation: launching
autom8 will spawn claude with an injected prompt, where we
define what we want to work on, once done we exit, autom8 picks
the new spec and converts it to json.
Second phase is implementation: agents will do what the plan
told them to.
Thirdly we have a review-correction loop.
Lastly (and optionally): commits and pr creation.
The state flow for a typical run:
┌──────────────────┐
│ Idle │
└────────┬─────────┘
│ start
▼
┌──────────────────┐
│ LoadingSpec │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ Initializing │
└────────┬─────────┘
│
┌───────────────────┼───────────────────┐
│ ▼ │
│ ┌──────────────────┐ │
│ │ PickingStory │◀────────┤
│ └────────┬─────────┘ │
│ │ │
│ ┌──────────────┼──────────────┐ │
│ │ incomplete │ all done │ │
│ ▼ │ │ │
│ ┌──────────────┐ │ │ │
│ │ RunningClaude│ │ │ │
│ └──────┬───────┘ │ │ │
│ │ │ │ │
│ ▼ │ │ │
│ ┌──────────────┐ │ │ │
issues ──▶ │ │ Reviewing │ │ │ │
found │ └──────┬───────┘ │ │ │
│ │ │ pass │ │ │
│ │ ▼ │ │ │
│ │ ┌──────────────┐ │ │ │
│ │ │ Committing │ │ │ │
│ │ └──────┬───────┘ │ │ │
│ │ │ │ │ │
│ └────────┴──────────┘ │ │
│ │ │
▼ ▼ │
┌──────────────┐ ┌──────────────┐
│ Correcting │ │ CreatingPR │
└──────┬───────┘ └──────┬───────┘
│ │
└──────────▶ back to Reviewing ▼
┌──────────────┐
│ Completed │
└──────────────┘
State is persisted after every transition.
Cumulative Context Architecture
Each Claude invocation starts fresh with zero knowledge of what happened before. For single-shot tasks this is fine. For complex workflow/implementations where we want to keep relatively low context per agent but share some level of context to avoid doing too much work per agent we need something a little more sophisticated.
Consider implementing three related features: authentication, user profiles, and settings. Story 1 creates the auth module. Story 2 needs to know about that module to build profiles. Story 3 needs to know about both to build settings that integrate with them.
autom8 solves this with the ProjectKnowledge struct:
pub struct ProjectKnowledge { /// Known files and their metadata, keyed by path pub files: HashMap<PathBuf, FileInfo>, /// Architectural decisions made during the run pub decisions: Vec<Decision>, /// Code patterns established during the run pub patterns: Vec<Pattern>, /// Changes made for each completed story pub story_changes: Vec<StoryChanges>, /// Baseline commit hash when the run started pub baseline_commit: Option<String>, }
After each agent completes, we captures knowledge from two sources:
- Git diffs: What files were created, modified, or deleted
- Agent output: Semantic information the LLM provides about decisions and patterns
The agent is prompted to output structured context blocks:
<files-context> src/auth.rs | JWT authentication module | [authenticate, verify_token] src/main.rs | Application entry | [main] </files-context> <decisions> Auth method | JWT | Stateless, scalable, well-supported </decisions> <patterns> Use Result<T, AuthError> for auth operations </patterns>
This gets parsed and merged into the knowledge base:
pub struct StoryChanges { pub story_id: String, pub files_created: Vec<FileChange>, pub files_modified: Vec<FileChange>, pub files_deleted: Vec<PathBuf>, pub commit_hash: Option<String>, } pub struct FileChange { pub path: PathBuf, pub additions: u32, pub deletions: u32, pub purpose: Option<String>, pub key_symbols: Vec<String>, }
When the next story starts, autom8 injects this knowledge into the prompt. The agent sees a table of files touched so far, architectural decisions that were made, and patterns it should follow. This context injection is automatic, stories don't need to explicitly reference each other. We have git based non-llm fallbacks for when agents misbehave and don't output file context/decision. Note context injection going from one agent to the next is a sub millisecond op: there's no llm invocation for this.
Between stories, the user
might make unrelated changes—updating dependencies, editing configs, etc.
autom8 tracks which files it touched via the baseline_commit
and filters subsequent diffs to only include "our" changes:
pub fn filter_our_changes(&self, all_changes: &[DiffEntry]) -> Vec<DiffEntry> { let our_files = self.our_files(); all_changes .iter() .filter(|entry| { // Include if it's a new file (we created it) if entry.status == DiffStatus::Added { return true; } // Include if we've touched it before our_files.contains(&entry.path) }) .cloned() .collect() }
Each story in a run has access to accumulated context from all previous stories, without the noise of unrelated changes. Later agents build on earlier work rather than rediscovering it.
Type-Safe Error Handling
Orchestration code being inherently complex (there are dozens of failure modes: file not found, invalid JSON, git errors, Claude crashes, timeouts, network issues)...
We use exhaustive enums for all error types, with compiler enforced all variant handling:
use thiserror::Error; #[derive(Error, Debug)] pub enum Autom8Error { #[error("Spec file not found: {0}")] SpecNotFound(PathBuf), #[error("Invalid spec format: {0}")] InvalidSpec(String), #[error("No incomplete stories found in spec")] NoIncompleteStories, #[error("Claude process failed: {0}")] ClaudeError(String), #[error("Claude process timed out after {0} seconds")] ClaudeTimeout(u64), #[error("State file error: {0}")] StateError(String), #[error("No active run to resume")] NoActiveRun, #[error("Run already in progress: {0}")] RunInProgress(String), #[error("IO error: {0}")] Io(#[from] std::io::Error), #[error("JSON error: {0}")] Json(#[from] serde_json::Error), #[error("Review failed after 3 iterations")] MaxReviewIterationsReached, // ... more variants }
Each variant has a human-readable message, and the #[from]
attribute enables automatic conversion from underlying error types.
Outcome enums follow the same pattern. Rather than returning booleans or magic strings, operations return typed results:
#[derive(Debug, Clone, PartialEq)] pub enum ReviewResult { Pass, IssuesFound, Error(ClaudeErrorInfo), } #[derive(Debug, Clone, PartialEq)] pub enum CorrectorResult { Complete, Error(ClaudeErrorInfo), }
When handling review results, the match is exhaustive:
match review_result { ReviewResult::Pass => { // All good, proceed to commit state.transition_to(MachineState::Committing); } ReviewResult::IssuesFound => { // Need correction if state.review_iteration < 3 { state.transition_to(MachineState::Correcting); } else { return Err(Autom8Error::MaxReviewIterationsReached); } } ReviewResult::Error(info) => { // Claude failed, decide what to do log::error!("Review failed: {}", info.message); state.transition_to(MachineState::Failed); } }
The benefit of this approach compounds over time: adding a new error type or state variant causes compile errors everywhere that needs updating.
Self-Correcting Review Loops
We use a simple bounded review loop. After all stories are marked complete, a reviewer agent checks the work against the spec. If issues are found, a corrector agent attempts fixes. This cycles up to n times before giving up gracefully.
The flow looks like this:
PickingStory (all complete)
│
▼
Reviewing ◀───────────┐
│ │
┌────┴────┐ │
│ │ │
Pass IssuesFound │
│ │ │
▼ ▼ │
Committing Correcting ───┘
(if iteration < n)
The reviewer agent gets the full spec context and writes issues to a file if any are found:
pub fn run_reviewer<F>( spec: &Spec, iteration: u32, max_iterations: u32, mut on_output: F, ) -> Result<ReviewResult> where F: FnMut(&str), { let prompt = build_reviewer_prompt(spec, iteration, max_iterations); // ... run Claude ... // Check if review file exists and has content let review_path = Path::new(REVIEW); if review_path.exists() { match std::fs::read_to_string(review_path) { Ok(content) if !content.trim().is_empty() => Ok(ReviewResult::IssuesFound), Ok(_) => Ok(ReviewResult::Pass), Err(e) => Ok(ReviewResult::Error(/* ... */)), } } else { Ok(ReviewResult::Pass) } }
If issues are found, the corrector agent reads that file and attempts fixes.
// In the main loop state.review_iteration += 1; match run_reviewer(&spec, state.review_iteration, 3, on_output)? { ReviewResult::Pass => { state.transition_to(MachineState::Committing); } ReviewResult::IssuesFound => { if state.review_iteration >= 3 { return Err(Autom8Error::MaxReviewIterationsReached); } state.transition_to(MachineState::Correcting); } ReviewResult::Error(e) => { /* handle */ } }
When the limit is hit, autom8 leaves the review file in place. The human can review the remaining issues, make manual fixes, and re-run if needed.
Git Worktrees: Parallel Execution
When worktrees are enabled (which they are by default), autom8 creates an isolated worktree for each session. The session ID is deterministic is just a SHA-256 hash of the repo path and branch name, truncated to 8 hex chars. Same inputs always produce the same session, so resuming a run finds the right worktree automatically.
pub struct WorktreeInfo { pub path: PathBuf, pub branch: String, pub session_id: String, } pub enum WorktreeResult { Created(WorktreeInfo), Existing(WorktreeInfo), Conflict { branch: String, existing_path: PathBuf }, }
The session ID generation is straightforward:
fn generate_session_id(repo_path: &Path, branch: &str) -> String { let mut hasher = Sha256::new(); hasher.update(repo_path.to_string_lossy().as_bytes()); hasher.update(b":"); hasher.update(branch.as_bytes()); let hash = hasher.finalize(); hex::encode(&hash[..4]) // first 8 hex chars }
Before creating a worktree, autom8 checks for branch conflicts.
Git doesn't allow two worktrees to have the same branch checked out.
If another session is already using the branch, we return a
Conflict instead of silently breaking:
// In ensure_worktree() for wt in existing_worktrees { if wt.branch == branch && wt.path != expected_path { return Ok(WorktreeResult::Conflict { branch: branch.to_string(), existing_path: wt.path, }); } }
The worktree path pattern is configurable via
worktree_path_pattern in the config. The default is
{repo}-wt-{branch}, placing worktrees as siblings of
the main repo directory. After a run completes, worktrees can be
automatically cleaned up if worktree_cleanup is enabled.
Follow-Up: The Improve Command
What happens when you come back to a feature branch a day later and need refinements, bug fixes, or extensions?
autom8 improve is designed for this. It gathers context from
up to three layers and spawns an interactive Claude session with full
awareness of what was previously implemented. You describe what you want
changed, and the session starts with all the relevant history already
loaded. This saves you time instead of either re-running autom8 or
running a claude session to make changes to what autom8 did.
The context model has three layers: git context (always present), the original spec (if it still exists), and accumulated project knowledge (if a previous run captured it). Each layer is optional except git, which is derived directly from the branch:
pub struct FollowUpContext { pub git: GitContext, pub spec: Option<Spec>, pub knowledge: Option<ProjectKnowledge>, } pub struct GitContext { pub branch: String, pub commits: Vec<CommitInfo>, pub diff_summary: String, pub files_changed: Vec<PathBuf>, }
GitContext is reconstructed from the branch itself: the
commits since divergence from main, a diff summary, and the list of
files touched. This is always available regardless of whether the
original run used autom8 or not — any feature branch has enough
git history to build useful context.
The richness of the session depends on how many layers are present. autom8 uses a simple 1-3 scale:
impl FollowUpContext { /// 1 = git only, 2 = git + one of spec/knowledge, 3 = all three pub fn richness_level(&self) -> u8 { 1 + self.spec.is_some() as u8 + self.knowledge.is_some() as u8 } }
At level 1 (git only), Claude sees the branch diff and commit messages. At level 2, it also gets either the spec with acceptance criteria or the knowledge base with architectural decisions. At level 3, it has the full picture: what was planned, what was decided during implementation, and exactly what changed. The richer the context, the less you need to re-explain when asking for changes.
UI/UX Design
autom8 has three display modes: a streaming CLI for running tasks, an interactive TUI for monitoring, and a native desktop GUI for richer workflows. All prioritize simplicity and consistency over showing everything.
CLI Output: Filtering the Noise
Claude produces lots of output: tool calls, file reads, thinking blocks, status messages... We filter this to only output what happens, and we always display the same nb of chars at the same pos for consistency.
fn should_display(event: &StreamEvent) -> bool { match event { StreamEvent::Text(text) => !text.trim().is_empty(), StreamEvent::ToolUse { name, .. } => { // Show edits and writes, skip reads and searches matches!(name.as_str(), "Edit" | "Write" | "Bash") } StreamEvent::Thinking(_) => false, _ => false, } }
We get a clean stream that shows: state transitions, which story is being worked on, edits being made, and commands being run. You can follow progress without scrolling through hundreds of lines of file contents and tool metadata.
Full Claude output is still available in log files if you need to debug.
Phase banners mark transitions between stages:
━━━━━ RUNNING CLAUDE ━━━━━ Working on: US-001 Add login endpoint ━━━━━ REVIEWING ━━━━━ Iteration 1/3 ━━━━━ COMMITTING ━━━━━ feat(auth): implement login endpoint
These banners adapt to terminal width and provide consistent visual anchors as the run progresses.
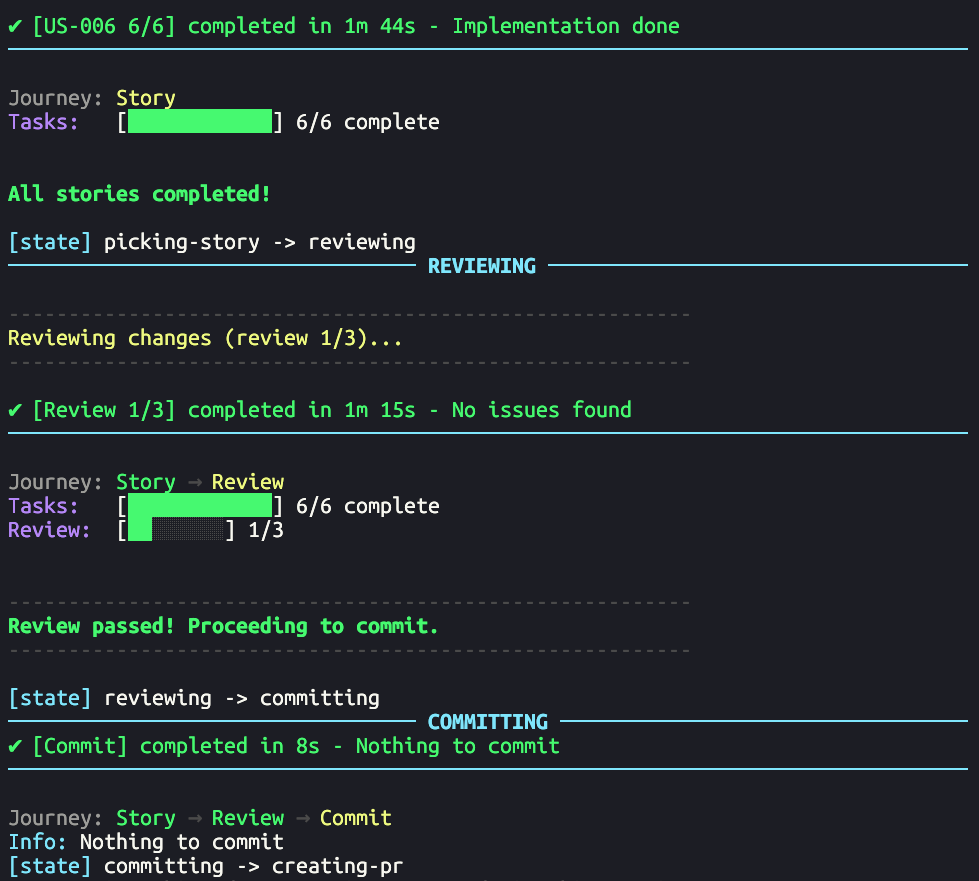
CLI output: filtered to show only relevant state transitions and actions
Monitor TUI: Real-Time Dashboard
The monitor TUI uses ratatui for an interactive dashboard. It polls state files from disk and renders a live view of all running projects.
The main view is a 2x2 quadrant grid showing active runs:
Navigation is arrows or vim-style: hjkl to move between quadrants,
n/p to paginate when there are more than four runs, and
Tab to switch views. Three views are available: active runs,
project list, and run history.
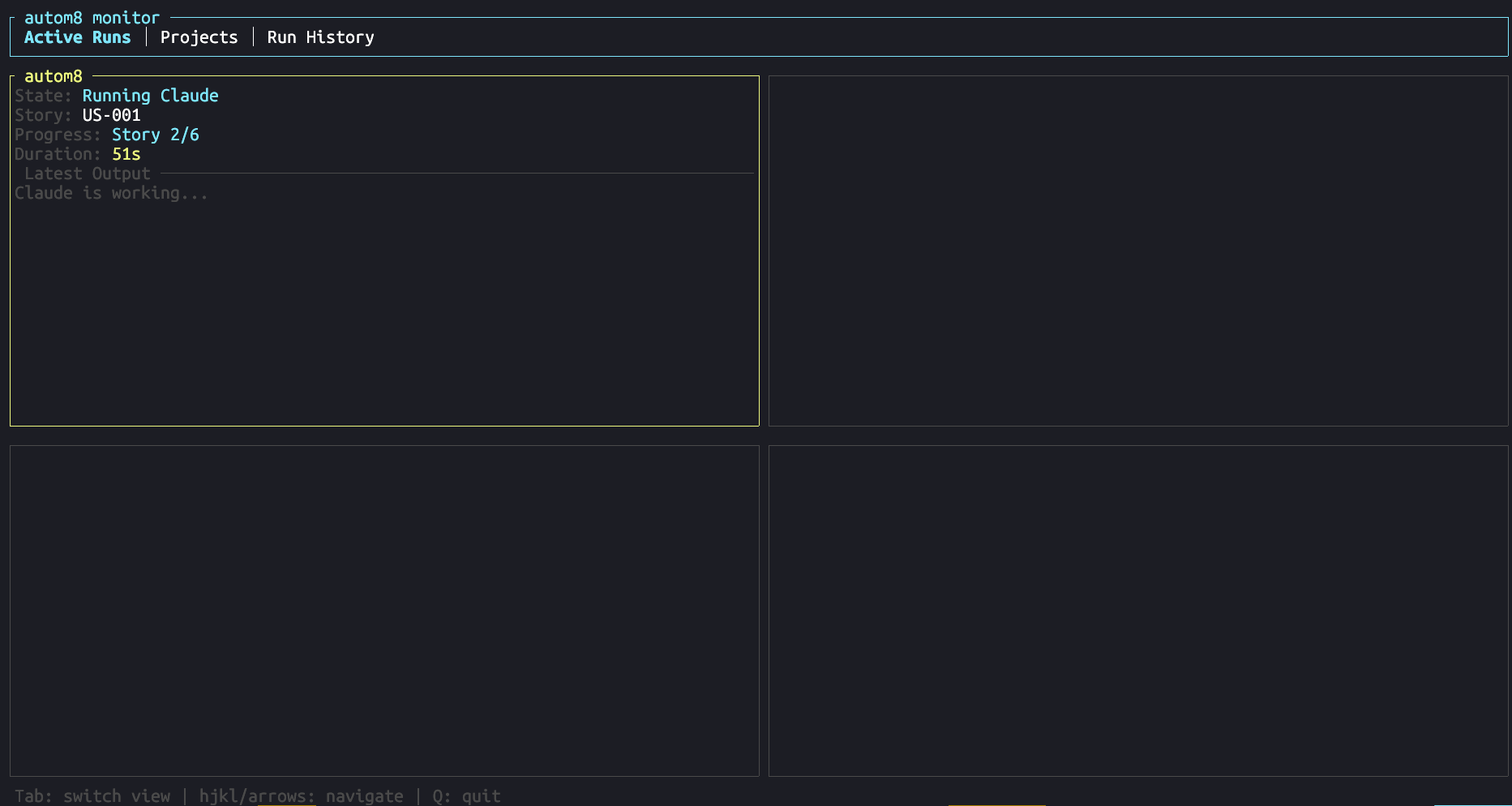
Monitor TUI: real-time dashboard with state and progress at a glance
Desktop GUI
The CLI and TUI are great for headless monitoring and quick checks, but some workflows benefit from a richer interface. autom8 ships a native desktop GUI built with eframe/egui that provides visual config editing, spec creation through a chat interface, and detailed session views that would be impractical in a terminal.
The GUI uses a dynamic tab system. Each session, config editor, or spec chat opens in its own tab, so you can switch between monitoring a running session and editing the config for the next one without losing context. Session tabs show live session cards with state, progress, current story, and iteration count.
Output display uses a source selection model. For a running session, you see live streamed output. For a completed iteration, you can select any previous iteration's output to review what happened. When nothing is actively running, the card shows the final status and summary. This three-tier approach (live output, iteration output, status) keeps the display relevant regardless of session state.
The config editor renders the TOML config as a form with toggles and text fields, validates changes before writing, and supports both global and project-level configs. Spec creation works through a chat panel where you describe what you want to build, and autom8 generates the spec JSON, the same flow as the CLI but with a visual conversation history.
Desktop GUI: live session monitoring with output stream and story status
Config
Config lives at ~/.config/autom8/config.toml, project specific config: ~/.config/autom8/"project_xyz"/config.toml and is automatically created when running autom8 for the first time or in another directory where we want to do work. Project specific configs take precedence over global config.
The config struct captures what features are enabled:
pub struct Config { pub review: bool, // Run reviewer/corrector loop? pub commit: bool, // Create git commits? pub pull_request: bool, // Create GitHub PR? pub pull_request_draft: bool, // Create PR as draft? pub worktree: bool, // Use git worktrees for isolation? pub worktree_path_pattern: String, // e.g. "{repo}-wt-{branch}" pub worktree_cleanup: bool, // Remove worktree after run? }
The new fields cover worktree isolation (worktree,
worktree_path_pattern, worktree_cleanup) and
draft PRs (pull_request_draft). Config is validated at
load time — enabling pull_request without
commit is an error, since there's nothing to push.
Config gets snapshotted at run start and stored in the state. This ensures resumed runs use the same settings they started with, even if the config file changes:
pub struct RunState { // ... /// Configuration snapshot taken at run start #[serde(default)] pub config: Option<Config>, // ... } /// Get the effective config for this run pub fn effective_config(&self) -> Config { self.config.clone().unwrap_or_default() }
Conclusion
Our goal with autom8 is to have a simple, fast, somewhat sophisticated and robust tool that facilitates using Claude for complex tasks by doing sane context window optimization, knowledge sharing between agents, features baked in (commits, pr's, reviews, worktrees) without user hassle and without noise.
It's published on crates.io and works well for complex/long tasks where a single claude instance's context window would grow quite large.
github.com/louisboilard/autom8 | crates.io